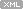
Intel NetBurst Architecture는 인텔이 IA-32 프로세서를 위한 실행환경이다. NetBurst의 기본적인 아키텍처를 이해하는 것은 거의 모든 IA-32 코드 생성기가 사용하는 최적화 지침에 대한 이론적 근거를 설명하는 것이므로 중요하다.
μops(Micro-Ops)
IA-32 프로세서는 프로세서가 지원하는 각 명령을 구현하기 위해서 마이크로 코드를 이용한다. 마이크로 코드는 본질적으로 프로세서 안의 다른 프로그래밍 계층이라고 할수있다. 이는 매우 단순한 연산 -매우 속도가 빠른, 만을 수행하는 아주 기본적인 핵심 부분을 프로세서가 포함하고 있다는 의미다. 비교적 복잡한 IA-32명령을 구현하기 위해 프로세서는 모든 명령 셋에 대한 마이크로 코드를 마이크로 ROM에 포함하고 있다.
마이크로 ROM에서 각 명령에 대한 아이크로 코드를 끊임없이 가져오는 작업은 성능상의 심각한 병목 현상을 야기시킨다. 따라서 IA-32 프로세서는 execution trace cache라는 것을 둬서 자주 사용되는 명령에 대한 마이크로 코드를 캐싱해 놓는다.
Pipeline(파이프라인)
기본적으로 CPU 파이프라인은 프로그램 명령을 해석하고 실행하는 공장의 조립라인과 비슷하다. 명령이 파이프라인에 입력되면 명령은 프로세서가 처리해야 하는 몇 개의 로우레벨 작업으로 세분화된다.
NetBurst 프로세서에서의 파이프라인은 다음과 같은 세 단계로 이뤄진다.
1. Front End 각 명령을 해석하고 해당 명령에 대한 μops 코드를 만들어 낸다. 그후 μops는 Out of Order Core에 입력된다.
2. Out of Order Core -Front End로부터 μops 코드가 입력되면 프로세서의 다양한 리소스 가용 상태에 따라 μops코드의 순서를 재조합한다. 이는 사용가능한 프로세서의 리소스를 최대한 활용해서 병렬 처리를 수행하기 위함이다. 이 과정을 거치면 하나의 CPU 클록 사이클 동안에 여러 개의 μops 코드를 동시에 수행할 수 있다. 하지만 Front End에 입력되는 명령 코드가 어떤 것이냐에 따라 이 단계에서의 작업이 가능한 것인지 전적으로 좌우된다.
3. Retirement Section -이 단계에서는 Out of Order Core 단계를 거치면서 원래의 명령 순서가 변경됐는지 확인한다.
명령 수행의 관점에서 보면 명령을 실제적으로 실행시키는 네 개의 실행 포트(각 포트는 모두 자신의 고유한 파이프라인을 가지고 있다)가 존재한다.
포트 0과 포트 1은 모두 2배속 ALU(Arithmetic Logical Unit)를 포함하고 있다는 사실에 주목하기 바란다. 이는 각 ALU가 하나의 클록 사이클 동안에 두 개의 연산을 수행할 수 있다는 것을 의미하며, IA-32 최적화의 매우 중요한 특징 중 하나다. 예를 들어 하나의 클록 사이클 동안에 4개(각 2배속 ALU마다 두개의 연산을 수행)의 덧셈이나 뺄셈 연산을 수행하는 것이 가능하다. 반면에 SIMD 부동소수점 연산이 아닌 경우에는 최소한 하나 이상의 클록 사이클이 요구된다. 실질적으로 부동소수점 연산을 수행하는(메모리와 FPU 스택 간의 데이터 이동은 다른 유닛이 수행한다) 유닛이 하나이기 때문이다.
컴파일러가 생산한 코드의 모호성에 대한 이론적인 근거를 확실히 제공하므로 NetBurst 아키텍처에 근거해서 컴파일을 수행하는 컴파일러의 컴파일 알고리즘이나 명령의 배치 순서를 이해하는 데 도움이 될것이다.
대부분의 IA-32 컴파일러는 NetBurst 아키텍처를 잘 알기에 코드 생성 단계에서 그것을 충분히 고려해 코드를 생성한다.
-- Secrets of Reverse Engineering
'Development' 카테고리의 다른 글
| Debugging Tools for Windows 6.12.2.633 download (0) | 2014.02.08 |
|---|---|
| mspdb100.dll mspdb80.dll Error Message가 나왔을때... (0) | 2013.02.12 |
| Low-Level Data Management (0) | 2013.02.04 |
| Clojure 개발환경 구축하기 - Getting Started with Eclipse and Counterclockwise (1) | 2012.12.27 |
| Just links: Released - Windows SDK for Windows 7 and .NET Framework 4 (1) | 2010.05.22 |


